この記事の第 1 部 は、競プロ Advent Calender 2 日目として公開されています。
第 1 部 2021-12-02 投稿第 2 部 2023-12-14 投稿
第 1 部:問題 Library Checker – Chromatic Number
Library Checker
Library Checker
問題文中の N N N n n n V V V ∣ V ∣ = n \vert V \vert = n ∣ V ∣ = n タイトルのように、この問題を解く計算量 O ( 2 n n ) O(2^n n) O ( 2 n n ) O ( 2 n ) O(2^n) O ( 2 n )
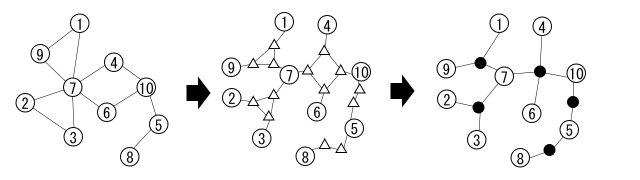
グラフの彩色数を用いた解法がある問題の例: (1-1:cp-unspoiler)
また、同じアルゴリズムを用いて和集合に関するある問題を高速に解けます。例: (2-1)
第 1 部:そもそも、そのアルゴリズムは何 頂点集合の部分集合 s s s k k k d p k [ s ] \mathrm{dp}_k[s] dp k [ s ] d p 1 \mathrm{dp}_1 dp 1
bitwise OR convolution を用いる O ( 2 n n 2 ) O(2^n n^2) O ( 2 n n 2 ) テーブル X X X X ^ \hat{X} X ^
頂点集合 s s s k k k t t t l l l s ∪ t s \cup t s ∪ t ( k + l ) (k+l) ( k + l ) 2 2 2 d p k \mathrm{dp}_k dp k d p l \mathrm{dp}_l dp l d p k + l \mathrm{dp}_{k+l} dp k + l d p k [ V ] \mathrm{dp}_k[V] dp k [ V ] V V V 1 ≤ k ≤ n 1 \leq k \leq n 1 ≤ k ≤ n k k k O ( 2 n n 2 ) O(2^n n^2) O ( 2 n n 2 ) O ( 2 n n log n ) O(2^n n \log n) O ( 2 n n log n )
1 1 1 O ( 2 n n ) O(2^n n) O ( 2 n n ) 彩色後のグラフについて、任意の k k k k k k n − k , n − k + 1 , … , n − 1 n-k,n-k+1, \ldots ,n-1 n − k , n − k + 1 , … , n − 1 k k k 0 0 0 1 1 1 n − k n-k n − k x x x x ≤ k − 1 x \leq k-1 x ≤ k − 1 0 , 1 , … , k 0,1, \ldots ,k 0 , 1 , … , k k k k d p k \mathrm{dp}_k dp k k k k O ( 2 n n ) O(2^n n) O ( 2 n n )
ちなみに、この方法では次の紹介する方法に比べて具体的な彩色の構築が容易です。
適当な値で割った余りを用いる O ( 2 n n ) O(2^n n) O ( 2 n n ) 以上で説明したアルゴリズムでは、 bitwise OR convolution の結果を真偽値に変換するため、 bitwise OR convolution の累乗を高速に求める方法(計算量 O ( 2 n n ) O(2^n n) O ( 2 n n ) P P P
bitwise OR convolution は以下の手順で行われます。
高速ゼータ変換
各点積
高速メビウス変換
まず、 d p 1 ^ \hat{\mathrm{dp}_1} dp 1 ^ k k k d p k [ V ] \mathrm{dp}_k[V] dp k [ V ] O ( 2 n ) O(2^n) O ( 2 n ) d p k [ V ] ≠ 0 \mathrm{dp}_k[V] \neq 0 dp k [ V ] = 0 k k k k = 1 , 2 , … , n k=1,2, \ldots ,n k = 1 , 2 , … , n k k k O ( 2 n n ) O(2^n n) O ( 2 n n )
出力が正しい保証がないと言いましたが、高々 n n n P P P
調べた限りでは、この方法で定数倍が小さいものが Library Checker によく提出されています。
以上をまとめて O ( 2 n ) O(2^n) O ( 2 n ) 以上の 2 2 2 O ( 2 n ) O(2^n) O ( 2 n ) d p k ^ \hat{\mathrm{dp}_k} dp k ^ P P P
d p 1 \mathrm{dp}_1 dp 1 O ( 2 n ) O(2^n) O ( 2 n ) Nyaan さんの提出 を参考にしました )。定数倍高速化の項で改めて解説します。
P ← 1 0 9 + 9 P \leftarrow 10^9+9 P ← 1 0 9 + 9 T [ i ] ← 1 T[i] \leftarrow 1 T [ i ] ← 1 ( i = 0 , 1 , … 2 n − 1 ) (i=0,1,\ldots 2^n-1) ( i = 0 , 1 , … 2 n − 1 ) A ← d p 1 ^ A \leftarrow \hat{\mathrm{dp}_1} A ← dp 1 ^ T [ i ] ← T [ i ] ⋅ ( − 1 ) popcount ( i ) m o d 2 ( i = 0 , 1 , … 2 n − 1 ) T[i] \leftarrow T[i] \cdot (-1)^{\text{popcount}(i) \bmod 2}\ (i=0,1,\ldots 2^n-1) T [ i ] ← T [ i ] ⋅ ( − 1 ) popcount ( i ) mod 2 ( i = 0 , 1 , … 2 n − 1 ) for k ← 1 , 2 , … , n \text{for }k \leftarrow 1,2, \ldots ,n for k ← 1 , 2 , … , n z ← 2 n − k \hspace{20px}z \leftarrow 2^{n-k} z ← 2 n − k T [ i ] ← ( T [ i ] A [ i ] ) m o d P ( i = 0 , 1 , … 2 z − 1 ) \hspace{20px}T[i] \leftarrow (T[i]A[i]) \bmod P\ (i=0,1,\ldots 2z-1) T [ i ] ← ( T [ i ] A [ i ]) mod P ( i = 0 , 1 , … 2 z − 1 ) T [ i ] ← ( T [ i ] + T [ i + z ] ) m o d P ( i = 0 , 1 , … z − 1 ) \hspace{20px}T[i] \leftarrow (T[i]+T[i+z]) \bmod P\ (i=0,1,\ldots z-1) T [ i ] ← ( T [ i ] + T [ i + z ]) mod P ( i = 0 , 1 , … z − 1 ) if ( ∑ i = 0 z − 1 T [ i ] ) m o d P = 0 \hspace{20px}\text{if }(\sum_{i=0}^{z-1}T[i]) \bmod P =0 if ( ∑ i = 0 z − 1 T [ i ]) mod P = 0 return k \hspace{40px}\text{return }k return k
いったい何を数え上げているんだ…? 適当な値で割った余りを用いる O ( 2 n n ) O(2^n n) O ( 2 n n )
各頂点を複数の色で塗ってよいとしたときの塗り方の個数
を数え上げることになります。
以上をまとめて O ( 2 n ) O(2^n) O ( 2 n )
各頂点を複数の色で塗ってよいが、頂点 n − 1 − i n-1-i n − 1 − i i i i
を数え上げることになります。
第 1 部:これを定数倍高速化します 概要 出力が 1 1 1 2 n 2^n 2 n 2 n − 1 2^{n-1} 2 n − 1 n − 1 n-1 n − 1
詳細 まず変数を定義します。
非負整数 E i E_i E i j j j i i i j j j
n n n k k k { 0 , 1 , 2 , … , n − 1 − k } \{0,1,2,\ldots ,n-1-k\} { 0 , 1 , 2 , … , n − 1 − k } d d d d p 2 k [ d ] \mathrm{dp2}_k[d] dp2 k [ d ] 0 0 0 d d d n − k , n − k + 1 , … n − 1 n-k,n-k+1, \ldots n-1 n − k , n − k + 1 , … n − 1 k k k k k k d p 2 k \mathrm{dp2}_k dp2 k
実際は 1 1 1 d d d この意味で非負整数と頂点集合を同一視する場合がある。
P P P
d p 2 k ^ \hat{\mathrm{dp2}_k} dp2 k ^ d p 2 k \mathrm{dp2}_k dp2 k
d p 1 ^ \hat{\mathrm{dp}_1} dp 1 ^ d p 1 ^ [ d ] \hat{\mathrm{dp}_1}[d] dp 1 ^ [ d ]
d d d 1 1 1
と解釈できます。頂点 h h h 2 h ≤ d < 2 h + 1 2^h \leq d \lt 2^{h+1} 2 h ≤ d < 2 h + 1
頂点 h h h d p 1 ^ [ d ∩ { h } ‾ ] \hat{\mathrm{dp}_1}[d \cap \overline{\{h\}}] dp 1 ^ [ d ∩ { h } ]
頂点 h h h h h h d p 1 ^ [ d ∩ { h } ‾ ∩ E h ‾ ] \hat{\mathrm{dp}_1}[d \cap \overline{\{h\}} \cap \overline{E_h}] dp 1 ^ [ d ∩ { h } ∩ E h ]
として、より小さい d d d d p 1 ^ [ 0 ] = 1 \hat{\mathrm{dp}_1}[0]=1 dp 1 ^ [ 0 ] = 1
d p 2 1 ^ \hat{\mathrm{dp2}_1} dp2 1 ^ 同様に場合分けし、動的計画法を導きます。
d p 2 1 ^ [ 0 ] = 1 \hat{\mathrm{dp2}_1}[0]=1 dp2 1 ^ [ 0 ] = 1 頂点 h h h d p 1 ^ [ d ∩ { h } ‾ ] \hat{\mathrm{dp}_1}[d \cap \overline{\{h\}}] dp 1 ^ [ d ∩ { h } ]
頂点 h h h
頂点 h h h n − 1 n-1 n − 1 0 0 0
隣接しない場合、 h h h d p 1 ^ [ d ∩ { h } ‾ ∩ E h ‾ ] \hat{\mathrm{dp}_1}[d \cap \overline{\{h\}} \cap \overline{E_h}] dp 1 ^ [ d ∩ { h } ∩ E h ]
オーバーフローの吟味
(2023/01/20 更新)
実は、 32 32 32 2 n 2n 2 n 32 32 32 m o d 2 32 \bmod2^{32} mod 2 32
(以降、 2023/01/20 追記) この部分は当時の勘違いにもとづいて書かれており、結果的には誤りではなかったものの誤解を招いた可能性がありました。申し訳ございません。
n = 20 n=20 n = 20 3 20 ≤ 3.5 × 1 0 9 < 2 32 3^{20}\leq 3.5\times 10^9\lt 2^{32} 3 20 ≤ 3.5 × 1 0 9 < 2 32 n = 26 n=26 n = 26 64 64 64 2 n 2n 2 n
全体をもう一度 除数 P P P O ( 2 n n ) O(2^n n) O ( 2 n n )
A ← d p 1 ^ A \leftarrow \hat{\mathrm{dp}_1} A ← dp 1 ^ T ← d p 2 1 ^ T \leftarrow \hat{\mathrm{dp2}_1} T ← dp2 1 ^ if E i = ∅ ( i = 0 , 1 , … n − 1 ) \text{if }E_i=\emptyset\ (i=0,1,\ldots n-1) if E i = ∅ ( i = 0 , 1 , … n − 1 ) return 1 \hspace{20px}\text{return }1 return 1 for k ← 2 , 3 , … , n \text{for }k \leftarrow 2,3, \ldots ,n for k ← 2 , 3 , … , n z ← 2 n − k \hspace{20px}z \leftarrow 2^{n-k} z ← 2 n − k T [ i ] ← T [ i ] A [ i ] ( i = 0 , 1 , … 2 z − 1 ) \hspace{20px}T[i] \leftarrow T[i]A[i]\ (i=0,1,\ldots 2z-1) T [ i ] ← T [ i ] A [ i ] ( i = 0 , 1 , … 2 z − 1 ) T [ i ] ← − T [ i ] + T [ i + z ] ( i = 0 , 1 , … z − 1 ) \hspace{20px}T[i] \leftarrow -T[i]+T[i+z]\ (i=0,1,\ldots z-1) T [ i ] ← − T [ i ] + T [ i + z ] ( i = 0 , 1 , … z − 1 ) T ← first half of T \hspace{20px}T \leftarrow \text{first half of }T T ← first half of T T ← M o ¨ bius transformed T \hspace{20px}T \leftarrow \text{Möbius transformed }T T ← M o ¨ bius transformed T if ( ∑ i = 0 z − 1 T [ i ] ) m o d P = 0 \hspace{20px}\text{if }(\sum_{i=0}^{z-1}T[i]) \bmod P =0 if ( ∑ i = 0 z − 1 T [ i ]) mod P = 0 return k \hspace{40px}\text{return }k return k T ← zeta transformed T \hspace{20px}T \leftarrow \text{zeta transformed }T T ← zeta transformed T
除数 P P P O ( 2 n ) O(2^n) O ( 2 n )
P ← 1 0 9 + 9 P \leftarrow 10^9+9 P ← 1 0 9 + 9 A ← d p 1 ^ A \leftarrow \hat{\mathrm{dp}_1} A ← dp 1 ^ T ← d p 2 1 ^ T \leftarrow \hat{\mathrm{dp2}_1} T ← dp2 1 ^ T [ i ] ← T [ i ] ⋅ ( − 1 ) popcount ( i ) m o d 2 ( i = 0 , 1 , … 2 n − 1 ) T[i] \leftarrow T[i] \cdot (-1)^{\text{popcount}(i) \bmod 2}\ (i=0,1,\ldots 2^n-1) T [ i ] ← T [ i ] ⋅ ( − 1 ) popcount ( i ) mod 2 ( i = 0 , 1 , … 2 n − 1 ) if E i = ∅ ( i = 0 , 1 , … n − 1 ) \text{if }E_i=\emptyset\ (i=0,1,\ldots n-1) if E i = ∅ ( i = 0 , 1 , … n − 1 ) return 1 \hspace{20px}\text{return }1 return 1 for k ← 2 , 3 , … , n \text{for }k \leftarrow 2,3, \ldots ,n for k ← 2 , 3 , … , n z ← 2 n − k \hspace{20px}z \leftarrow 2^{n-k} z ← 2 n − k T [ i ] ← ( T [ i ] A [ i ] ) m o d P ( i = 0 , 1 , … 2 z − 1 ) \hspace{20px}T[i] \leftarrow (T[i]A[i]) \bmod P\ (i=0,1,\ldots 2z-1) T [ i ] ← ( T [ i ] A [ i ]) mod P ( i = 0 , 1 , … 2 z − 1 ) T [ i ] ← T [ i ] + T [ i + z ] ( i = 0 , 1 , … z − 1 ) \hspace{20px}T[i] \leftarrow T[i]+T[i+z]\ (i=0,1,\ldots z-1) T [ i ] ← T [ i ] + T [ i + z ] ( i = 0 , 1 , … z − 1 ) if ( ∑ i = 0 z − 1 T [ i ] ) m o d P = 0 \hspace{20px}\text{if }(\sum_{i=0}^{z-1}T[i]) \bmod P =0 if ( ∑ i = 0 z − 1 T [ i ]) mod P = 0 return k \hspace{40px}\text{return }k return k
第 1 部:完成したものがこちら (2024-01-15 コンパイルエラー修正)
第 2 部:決定性 O ( 2 n ) O(2^n) O ( 2 n ) アルゴリズム 「以上をまとめて O ( 2 n ) O(2^n) O ( 2 n ) m o d P {}\bmod P mod P O ( 2 n ) O(2^n) O ( 2 n )
高速ゼータ変換をした後の配列に含まれる値は 2 n 2^n 2 n k k k ( 2 n ) k (2^n)^k ( 2 n ) k k k k
k k k O ( k 2 n − k ) O(k2^{n-k}) O ( k 2 n − k )
∑ k = 1 n k 2 n − k ≤ 2 n ∑ k = 1 ∞ k 2 − k = 2 n ∑ s = 1 ∞ 2 − s + 1 = 2 n 2 2 \sum_{k=1}^{n}k2^{n-k}\leq 2^n \sum_{k=1}^{\infty}k2^{-k} =2^n\sum_{s=1}^{\infty}2^{-s+1}=2^n 2^2 k = 1 ∑ n k 2 n − k ≤ 2 n k = 1 ∑ ∞ k 2 − k = 2 n s = 1 ∑ ∞ 2 − s + 1 = 2 n 2 2
と評価して O ( 2 n ) O(2^n) O ( 2 n )
実装 実装しました。 (2024-01-15 修正)
第 1 部での制作と比較すると、オーバーフローや除数による不正確さといった問題点が取り除かれたうえで、処理速度を維持することができました。
この実装では、正しく動作する範囲として 1 ≤ n ≤ 31 1\leq n\leq 31 1 ≤ n ≤ 31
実装のポイント メモリの戦略
第 1 部では一貫して、番号の大きい頂点から取り除くことで、アクセスする配列の範囲を狭めることを優先しました。今回は多倍長整数を扱うので 1 1 1
このため、頂点を取り除くときは番号の小さい頂点から順に取り除くことにして、配列を間引くように空間を減らすようにします。これにより、 k k k 1 1 1 2 k 2^k 2 k k + 1 k+1 k + 1
多倍長整数の演算
ゼータ変換の長さを半分にするステップでは、
1 1 1 a , b a,b a , b k k k x , y x,y x , y k + 1 k+1 k + 1 a x − b y ax-by a x − b y
という計算が繰り返されます。 a x ax a x b y by b y
また、彩色可能か判定するためにテーブルの値を足し引きするときは、符号・桁ごとに足し合わせてから繰り上がりを処理し、正の成分と負の成分それぞれの総和が一致するかどうか判定するように実装しました。
おわりに 第 1 部では地道な高速化で差を付けることにしていましたが、第 2 部では競プロでよく用いられる方法と比べて確かに高速な解法プログラムを作ることができました。ソースコード長もそんなに大きくありません。 Library Checker の問題設定において、競プロ用ライブラリとしてはかなり良いところに落ち着いているのではないでしょうか。